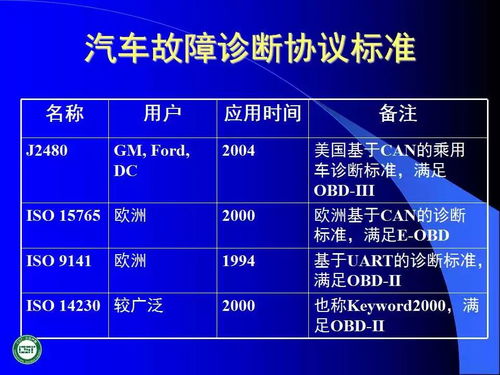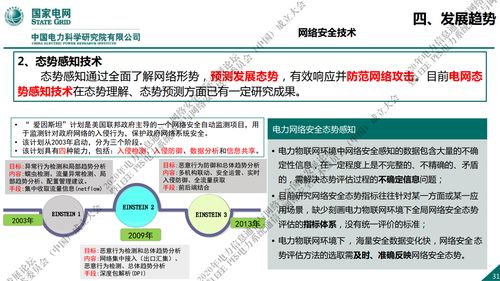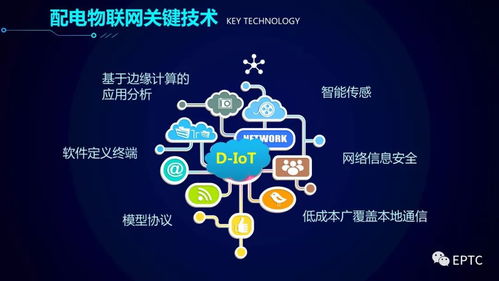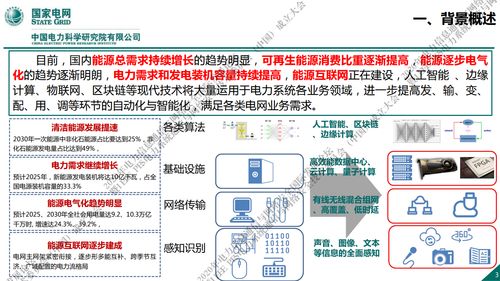
深度學習作為人工智能領域的核心技術之一,在過去幾十年中經歷了顯著的發展。本文將從深度學習的起源、核心技術的演進以及網絡開發的關鍵里程碑進行全面概述,旨在為讀者提供一個全局性的技術視角。
深度學習的根源可以追溯到20世紀中葉的神經網絡研究。早期,感知機模型由Frank Rosenblatt于1958年提出,它通過模擬人腦神經元的結構,實現了簡單的模式識別功能。由于計算能力的限制和理論上的不足,神經網絡在20世紀70年代至80年代陷入了第一次低潮期。直到1986年,反向傳播算法的提出為神經網絡訓練提供了有效方法,使得多層網絡得以實現,這標志著深度學習的前身——深度神經網絡的誕生。
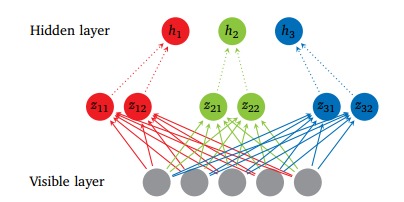
進入21世紀后,隨著大數據和計算硬件的飛速發展,深度學習迎來了復興。2006年,Geoffrey Hinton等人提出了深度信念網絡,通過無監督預訓練解決了深層網絡訓練難的問題。2012年,AlexNet在ImageNet競賽中取得突破性成果,利用卷積神經網絡(CNN)大幅提升了圖像識別準確率,這成為深度學習技術普及的關鍵轉折點。此后,循環神經網絡(RNN)和長短期記憶網絡(LSTM)在處理序列數據方面取得進展,而生成對抗網絡(GAN)和Transformer架構則在生成模型和自然語言處理領域掀起了革命。
在核心技術發展方面,深度學習從最初的淺層網絡演進到包含數十甚至數百層的深度架構。關鍵技術創新包括激活函數(如ReLU)的優化、正則化技術(如Dropout)的應用,以及優化算法(如Adam)的改進。這些進步不僅提高了模型性能,還降低了過擬合風險。同時,遷移學習和自監督學習等方法的引入,使得深度學習在數據稀缺場景下也能發揮強大作用。
在網絡技術開發上,開源框架如TensorFlow、PyTorch和Keras的興起極大地推動了深度學習的普及。這些工具提供了高效的編程接口,使研究人員和開發者能夠快速構建、訓練和部署復雜模型。硬件加速技術,如GPU和TPU的廣泛使用,顯著縮短了訓練時間,促進了大規模應用的實現。從計算機視覺到自然語言處理,再到自動駕駛和醫療診斷,深度學習網絡技術已滲透到各行各業。
深度學習將繼續與強化學習、聯邦學習等新興技術融合,推動人工智能向更通用、更高效的方向發展。盡管面臨可解釋性、數據隱私等挑戰,但通過持續的創新,深度學習有望在智能系統中扮演更核心的角色。從早期神經網絡到現代深度架構,深度學習的發展歷程體現了技術、數據和算法的協同進化,為人類社會的智能化轉型提供了堅實基礎。